在這次的探討中我們可以從學術研究中去探討,這次主要是要介紹一篇 Survey 論文 Making Images Real Again: A Comprehensive Survey on Deep Image Composition!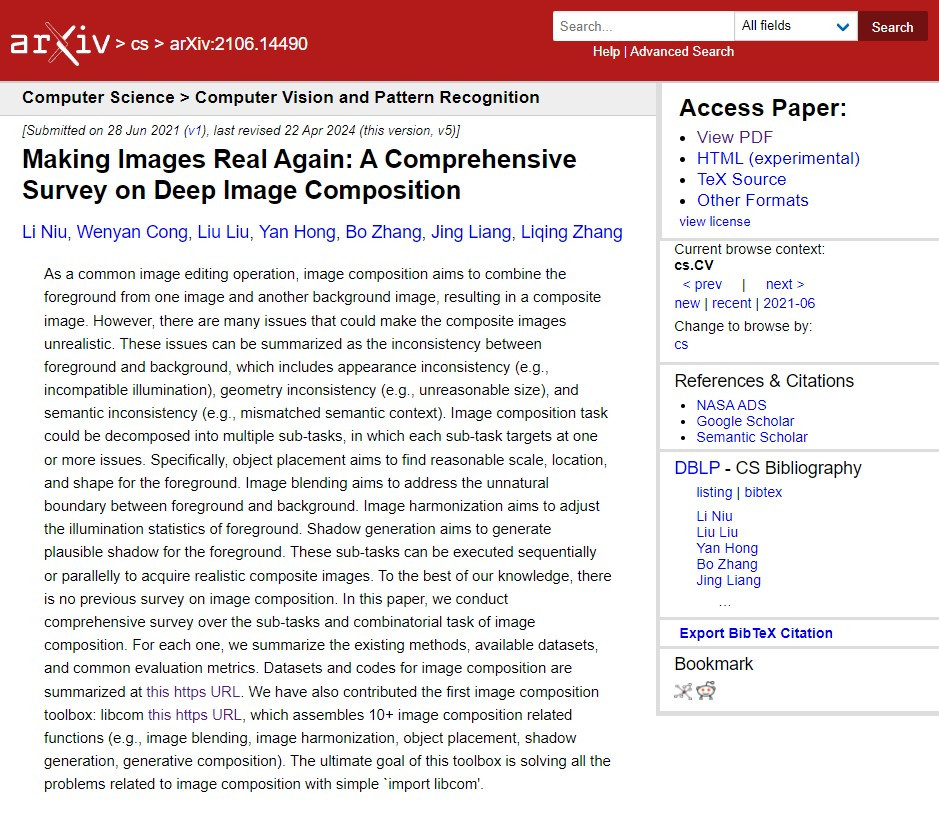
本文主要介紹影像合成任務的歷史解決方案,第一作者是由上海交大的教授 Li Niu(牛力)撰寫。圖像合成是個複雜的電腦視覺任務,除了透視、物品的合理大小&位置還有像是光影這類型複雜的子任務需要去解決,像是下方圖片是論文所提供的一個例子。
論文中所提的範例這篇論文將這個複雜的任務拆解為多個子任務去做調查:

其實之前已經有很多人去解決過相關的任務,接下來分別介紹之前其他人的解決方案。
物品置入涉及根據背景為置入物品找到合適的位置、大小和方向。
🐌 傳統方法
過去的方法通常利用固定規則來確定物品的適合位置。這種方法對某些特定任務可能特別高效,但無法廣泛應用。
(EX.Learning to Segment via Cut-and-Paste)
🐛 深度學習方法
進階一點的使用深度學習方式利用神經網路去做預測合理的位置,這些方法可以粗略分為兩種:1.特定類別 2.特定例子。舉個例子。
1.特定類別(category-specific object placement):根據背景圖像以及提供的物品類別去預測邊界框(Bounding Box),但這類型的方法相同的物品類別在不同的例子上可能會不適合。
2.特定例子(instance-specific object placement methods):這種方法會考慮物品的特徵與背景之間的關係。

影像混合的目標在於平滑化前景以及背景的過渡。讓合成的結果看起來更加自然。

圖像協調的目的是調整合成前景的顯示效果,使其在光照、顏色和色調上與背景匹配,解決因拍攝條件不同(如照明和相機設置)造成的不一致性。


如文字敘述所示,目標是想要為前景物品創造真實的陰影,以增強圖像之真實感。與圖像協調相似分為兩種方式去做實現:
🐌 基於渲染的作法
基於場景幾何資訊&光影去對物品做渲染,但這樣的作法會遇到幾個問題。
(1)資料收集困難:像是許多資料往往需要用戶手動輸入或是透過複雜的測量和估計過程獲得,往往繁瑣且難以實現的。
(2)估計的不準確性
(3)計算成本高昂
(4)依賴專業知識
(5)通用性問題
🐛 非基於渲染的作法
利用深度學習的像是自動編碼器或像是 GAN 的深度學習架構來預測陰影遮罩。(通常基於有無陰影的資料去進行訓練。)
隨著 diffusion 模型的流行,這類型的任務越來越熱門,前面講解的會是將合成影像的任務拆分成多個子任務,而接下來介紹的會是一體化的模型來完成此任務。目前的方法多數使用深度學習的方式去做,主要其實分為兩大類。token-to-object&object-to-object。
🐌Token-to-Object
將輸入數據直接映射到相應的物體或場景,通常會利用預訓練模型針對範例圖片去做微調(fine tune)
🐛Object-to-Object
通常會利用大量的(前景&背景&原始圖像)對照數據來去訓練 diffusion 模型,首先前景為從原始圖像去做裁剪,接著將背景圖像&邊界框的遮罩和帶噪音之圖像串聯去做輸入,而前景通常會透過交叉注意力機制(Cross Attention Cross Attention)去注入模型中。

https://doi.org/10.48550/arXiv.2106.14490


 iThome鐵人賽
iThome鐵人賽